Что такое SQL?
Для чего нужен SQL?
SQL - это язык программирования для написания запросов к реляционным базам данных. Аббревиатура происходит от английского Structured Query Language (язык стуктурированных запросов).
Команды, написанные на SQL, позволяют создавать и изменять базы данных, записывать информацию в таблицы (называемые также "отношениями"), извлекать из баз данных записи по установленным критериям, а также группировать, сортировать, соединять выходные данные и производить многие другие манипуляции с ними перед возвращением результата.
Более подробно обо всех приведенных возможностях, предоставляемых языком SQL, мы расскажем ниже.
Данная статья будет полезна как тем, кто только начинает работать с базами данных, так и более опытным пользователям языка SQL для восстановления в памяти забытой информации.
Самые популярные базы данных
Как было сказано выше, SQL работает с хранилищами данных. Вот список наиболее популярных из них:
| База |
|---|
| Oracle |
| MySQL |
| MS SQL Server |
| PostgreSQL |
А как же MongoDB, могут спросить те, кто уже начал знакомство с вопросами хранения информации
и слышали о других популярных решениях.
Отвечаем: MongoDB работает с документоориентированной моделью данных, а SQL используется с реляционной моделью.
О том, чем они отличаются, поговорим позже в другой статье.
Клиенты для работы с базами данных
Начать конечно же стоит с установки базы данных на ваш компьютер.
Мы уже привели ссылки для скачивания наиболее популярных вариантов.
Также, помимо самих баз данных вам потребуются программы-клиенты для взаимодействия с хранилищами и написания SQL-запросов.
Существует как клиенты, работающие только со "своей" базой данных, так и универсальные.
Мы не будем заниматься рекламой универсальных решений, поэтому приведем только те, которые поставляются вместе с базами данных,
либо рекомендуются разработчиками конкретной базы данных.
| База | Клиент |
|---|---|
| Oracle | Oracle Client |
| MySQL | MySQL Workbench |
| MS SQL Server | MS SQL Server Management Studio |
| PostgreSQL | pgAdmin |
Как написать SQL запрос?
Давайте попробуем создать первые скрипты, чтобы проверить SQL в действии. Использовать будем базу данных PostgreSQL и клиент pgAdmin.
В качестве предметной области выберем кинопроизводство, а первой таблицей будет таблица с должностями съемочной группы. Назовем ее titles.
Стоит отметить, что приведенные ниже примеры могут не работать в других базах. Но не нужно этого бояться, так как диалекты SQL для различных хранилищ основаны на стандарте языка SQL, поэтому отличия несущественны. Чем глубже вы станете погружаться в тонкости языка и технологии, тем проще вам будет переключаться с одной базы данных на другую. Однако, помимо стандарта каждая база данных обладает собственным набором дополнительных возможностей, на изучение которых может потребоваться значительное количество времени.
-- СОЗДАНИЕ ТАБЛИЦЫ
CREATE TABLE titles
(
id int PRIMARY KEY,
name text NOT NULL
);
Также есть команда DROP TABLE для удаления таблиц и ALTER TABLE для изменения. С ними вы легко сможете ознакомиться в документации по языку SQL.
Сохранение данных
Перейдем к следующему шагу - добавлению записей в нашу таблицу. Для этого используется команда INSERT. Давайте выполним следующий код:
-- ЗАПИСЬ ДАННЫХ В ТАБЛИЦУ
INSERT INTO titles (id, name)
VALUES
(1, 'Актер'),
(2, 'Композитор'),
(3, 'Режисер'),
(4, 'Космонавт');
В приведенном выше примере мы сознательно допустили ошибку. Слово 'Режиссер' написано с 1 буквой 'с'. В следующем подразделе будет показано, как это исправить.
Изменение данных
Итак, давайте исправим ошибку, допущенную ранее. Для этого нам понадобится инструкция UPDATE.
-- ИЗМЕНЕНИЕ ДАННЫХ В ТАБЛИЦЕ
UPDATE titles
SET name = 'Режиссер'
WHERE id = 3;
Удаление данных
Мы допустили еще одну ошибку - добавили должность 'Космонавт'.
Каждый должен профессионально заниматься своим делом, поэтому давайте удалим эту должность из нашего списка.
Для этого нам понадобится инструкция DELETE.
-- УДАЛЕНИЕ ДАННЫХ ИЗ ТАБЛИЦЫ
DELETE FROM titles
WHERE name = 'Космонавт';
Чтение данных
Приведенный ниже код демонстрирует простой способ чтения данных из таблицы. Запустим его и посмотрим, что мы имеем на текущий момент.
-- ИЗВЛЕЧЕНИЕ ДАННЫХ
SELECT id, name
FROM titles;
Результатом последовательного выполнения всех приведенных выше операций должно быть следующее:
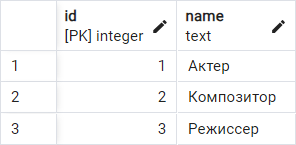
Реляционная модель данных
Немного усложним задачу и создадим еще несколько таблиц, чтобы получить следующую реляционную модель:
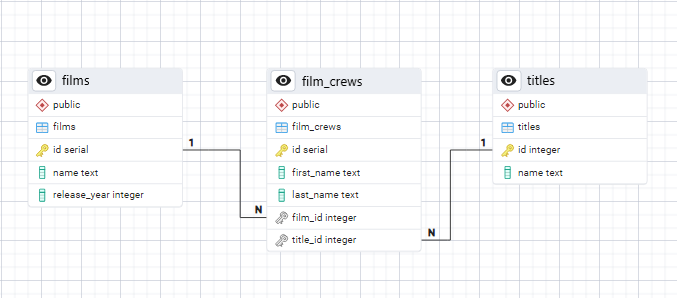
Добавим таблицу фильмов films:
-- СОЗДАНИЕ ТАБЛИЦЫ ФИЛЬМОВ
CREATE TABLE films
(
id int PRIMARY KEY,
name text NOT NULL,
release_year int NOT NULL
);
-- ЗАПИСЬ ДАННЫХ В ТАБЛИЦУ
INSERT INTO films (id, name, release_year)
VALUES
(1, 'Приключения Шерлока Холмса и доктора Ватсона', 1979),
(2, 'Двадцать шесть дней из жизни Достоевского', 1980);
и таблицу съемочных групп "film_crews":
-- СОЗДАНИЕ ТАБЛИЦЫ ДЛЯ СЪЕМОЧНЫХ ГРУПП
CREATE TABLE film_crews
(
id serial PRIMARY KEY,
first_name text NOT NULL,
last_name text NOT NULL,
film_id int REFERENCES films(id),
title_id int REFERENCES titles(id)
);
-- ЗАПИСЬ ДАННЫХ В ТАБЛИЦУ
INSERT INTO film_crews (first_name, last_name, film_id, title_id)
VALUES
('Василий', 'Ливанов', 1, 1),
('Виталий', 'Соломин', 1, 1),
('Владимир', 'Дашкевич', 1, 2),
('Игорь', 'Масленников', 1, 3),
('Евгения', 'Симонова', 2, 1),
('Анатолий', 'Солоницин', 2, 1),
('Ираклий', 'Габели', 2, 2),
('Александр', 'Зархи', 2, 3);
-- ИЗВЛЕЧЕНИЕ ДАННЫХ
SELECT first_name, last_name, film_id, title_id
FROM film_crews
Результатом последовательного выполнения данных операций будет следующее:
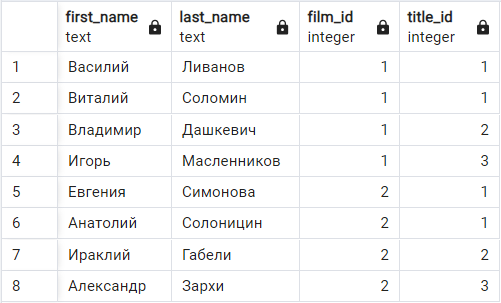
Cоединение таблиц при помощи инструкии JOIN
Как видите, все работает. Но, здесь есть два существенных недостатка:
- поле film_id показывает цифру, а хотелось бы видеть название фильма.
- поле title_id показывает цифру, а хотелось бы видеть должность человека в проекте.
Давайте попробуем исправить это.
На помощь нам и приходит реляционная модель и способность SQL работать с ней.
Чтобы "подтащить" данные из связных таблиц воспользуемся инструкцией языка INNER JOIN.
-- ИЗВЛЕЧЕНИЕ ДАННЫХ С ПРИСОЕДИНЕНИЕМ
SELECT f.name as film, fc.first_name, fc.last_name, t.name as title
FROM film_crews fc
INNER JOIN films f on f.id = fc.film_id
INNER JOIN titles t on t.id = fc.title_id
Обратите внимание на такие новшества в нашем запросе, как f, fc, t, as film и as title.
Это псевдонимы и используются они в тех случаях, когда нам нужно явно указать, из каких таблиц мы производим выборку конкретных столбцов.
Можно было бы обойтись и названиями самих таблиц, но они слишком длинные, поэтому обычно и прибегают к использованию псевдонимов.
Стоит также отметить, что псевдонимы можно вводить как с использованием as (as title), так и без него, что и показано в примере выше.
Теперь результат намного лучше, так как мы видим название фильмов и должности участников:
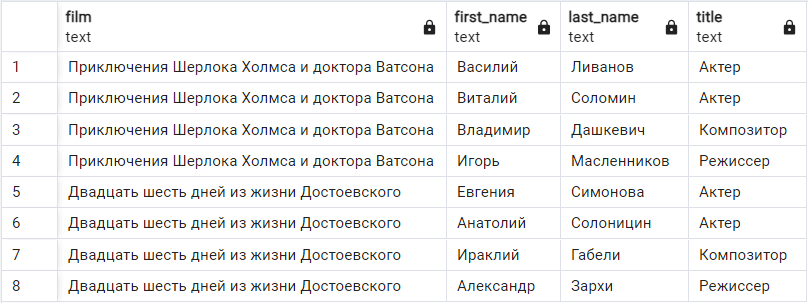
В языке SQL дополнительно присутствуют еще несколько вариантов соединений таких, как LEFT JOIN, RIGHT JOIN, FULL JOIN и CROSS JOIN. Попробуйте самостоятельно поэкспериментировать с этими видами соединений, чтобы понять, в каких случаях их стоит применять.
Инструкция WHERE
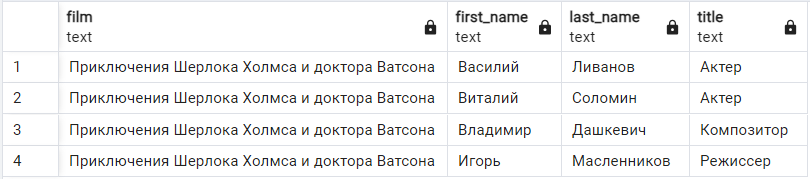
Давайте еще немного поиграем с нашими данными. Предположим, что нам потребовалось извлечь из базы данные только об одном фильме:
-- ИЗВЛЕЧЕНИЕ ДАННЫХ С УСЛОВИЕМ WHERE
SELECT f.name as film, fc.first_name, fc.last_name, t.name as title
FROM film_crews fc
INNER JOIN films f on f.id = fc.film_id
INNER JOIN titles t on t.id = fc.title_id
WHERE film_id = 1
Обратите внимание на то, что в WHERE film_id = 1 мы не использовали псевдоним f.
Все дело в том, что кроме таблицы film_crews такой колонки больше нигде нет.
А следовательно, транслятору языка не придется "ломать голову" с неоднозначностью.
Если бы в таблице titles вместо id мы использовали title_id тогда нужно было бы указать, о какой таблице идет речь через имя или псевдоним.
Возможно, в каких-то базах данных допустимо указание имени без псевдонима или таблицы, но PostgreSQL, в которой тестируются данные примеры, ругается на неоднозначность инструкции.
Представления (VIEW)
Предположим, что написанный запрос мы используем достаточно часто в других своих запросах, и не хотели бы каждый раз включать такой большой объем кода в них.
Для этого можно использовать представления (VIEW).
Создадим одно:
-- СОЗДАНИЕ ПРЕДСТАВЛЕНИЯ
CREATE VIEW sherlok_crew AS
SELECT f.name as film, fc.first_name, fc.last_name, t.name as title
FROM film_crews fc
INNER JOIN films f on f.id = fc.film_id
INNER JOIN titles t on t.id = fc.title_id
WHERE film_id = 1
Выполним запрос с условием к нашему вновь-созданному представлению 'sherlok_crew':
-- ИЗВЛЕЧЕНИЕ ДАННЫХ ИЗ ПРЕДСТАВЛЕНИЯ С УСЛОВНИЕМ WHERE
SELECT *
FROM sherlok_crew
WHERE TITLE = 'Актер'
Посмотрим на результат:

Существует еще один тип - материализованные представления.
Их отличие в том, что при создании - происходит физическое копирование данных результата запроса в представление.
Однако, при изменении исходных таблиц, данные в материализованные представления не подтягиваются автоматически.
Для этого нужно явно дать команду на синхронизацию данных.
Еще одно отличие обычного представления от материализованного состоит в том, что при работе с обычным можно производить вставку, обновление и удаление.
Материализованное же предтсавление разрешает исключительно чтение данных.
Агрегирование
Довольно часто при работе с базами данных появляется требование посчитать количество записей с определенным условием. Для этого в SQL предусмотрена агрегатная функция COUNT. Проверим ее в деле:
-- ПОДСЧЕТ КОЛИЧЕСТВА АКТЕРОВ В ФИЛЬМЕ
SELECT film, COUNT(*) as actors
FROM sherlok_crew
WHERE TITLE = 'Актер'
GROUP BY film
В этом запросе мы также применили инструкцию GROUP BY, которая позволила нам сгрупировать результат по названию фильма. Она часто будет вам встречаться в запросах, в которых используются функции агрегирования.
Ожидаемый результат - 2 актера:

Рекомендуем самостоятельно ознакомиться с расширенным списком агрегатных функций SQL: MIN, MAX, AVG, SUM и др.
Оператор LIKE
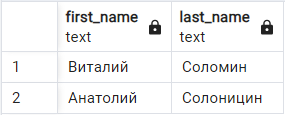
Бывает, что мы не знаем точно критерии, по которым необходимо провести выборку, но помним только часть слова. Например, мы знаем, что фамилия актера начинается на "Сол". В SQL для этого предусмотрен специальных оператор - LIKE. Продемонстрируем его на примере:
-- ВЫБОРКА ПО ЧАСТИ СЛОВА
SELECT first_name, last_name
FROM film_crews
WHERE last_name LIKE 'Сол%';
В результате получим двух актеров с фамилией, начинающейся на 'Сол':
Знак процента (%) нужно ставить вначале - '%ин', если требуется найти записи, заканчивающиеся на определенную последовательность символов. Если требуется провести выборку по некоторой последовательности символов внутри строки, то нужно обернуть их с двух сторон: %ло%.
Итоги
Как видите, вроде бы не очень сложно. Однако, освещенная часть материала - это даже не верхушка айсберга, а всего лишь его небольшая часть.
Хотя на первых порах разработки хранилищ с данными приведенной информации может быть достаточно.
Тем не менее, знаний одного лишь SQL не хватит для создания современных полноценных приложений.
Для этого понадобятся еще несколько языков программирования и десятки, а то и сотни дополнительных инструментов, помогающих современным разработчикам создавать сложные решения.
Желаем вам достичь вершин в поставленных целях.
Дата публикации: 01.08.2024
Автор: Вальчук Александр
Нужна команда программистов?
Профессионалы компании АЭРОЛОГОС оказывают услуги разработки программного обеспечения. Мы предоставляем сервис по созданию программных решений любого уровня сложности под требования клиента. Более подробно о нашем подходе к разработке и накопленном опыте можно ознакомиться по следующей ссылке: Разработка программного обеспечения на заказ
Контактная информация
По любым вопросам касаемо наших продуктов или услуг Вы можете связаться с нами, используя следующую контактную информацию:
- Организация: ООО «АЭРОЛОГОС»
- Адрес: 220018, Республика Беларусь, г. Минск, ул. Максима Горецкого 14, пом. 503, кабинет 4-63
- Электронный адрес: contact@aerologos.by
- Телефон: +375 (33) 662-05-81
- Вебсайт: https://aerologos.by
- Форма обратной связи